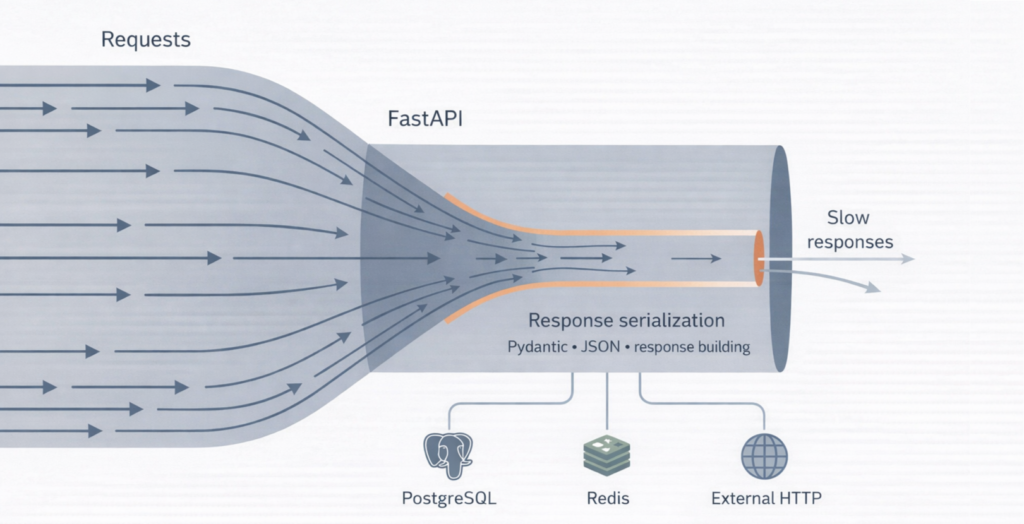
FastAPI często wybiera się ze względu na szybkość, wygodę i asynchroniczność. Ale w jednym z naszych projektów API przy obciążeniu zaledwie 150 RPS zaczęło odpowiadać po 3–5 sekundach, a czasami kończyło się timeoutami.
Jednocześnie po stronie infrastruktury wszystko wyglądało całkiem normalnie:
- CPU utrzymywało się na poziomie 35–40%
- PostgreSQL nie pokazywał długich zapytań
- sieć również nie wyglądała na wąskie gardło
Na pierwszy rzut oka nie było żadnych wyraźnych problemów. A jednak użytkownicy czekali na odpowiedź całymi sekundami. Sprawdźmy, co się wydarzyło.
Architektura serwisu
Stack był całkiem typowy:
- FastAPI
- PostgreSQL
- SQLAlchemy 2.0 (async)
- Redis
- Docker + Kubernetes
- Uvicorn + Gunicorn
Jeden z endpointów w uproszczonej formie wyglądał tak:
@router.get("/orders/{order_id}")
async def get_order(order_id: int, db: AsyncSession = Depends(get_db)):
order = await order_service.get_order(order_id, db)
return orderWewnątrz handlera działy się trzy rzeczy:
- zapytanie do PostgreSQL
- zapytanie do Redis
- zapytanie HTTP do zewnętrznego serwisu
I wszystko to przez async. Wydawałoby się, że nie ma tu skąd brać się opóźnieniom.
Objawy pod obciążeniem
Obraz degradacji był bardzo charakterystyczny:
Gdy latency rośnie właśnie w taki schodkowy sposób, a baza danych w tym czasie “milczy”, zwykle warto patrzeć w dwóch kierunkach:
- gdzieś dobijamy do ograniczenia CPU, choć nie widać tego po ogólnym wykorzystaniu
- albo istnieje wąskie gardło w event loop, przez które serwis zaczyna działać jak kolejka
Profilowanie
Najpierw uruchomiliśmy py-spy:
py-spy top --pid <pid>Wynik okazał się zaskakujący:
- około 40% czasu trafiało w
json.dumps - około 30% w serializację Pydantic
- około 20% w przetwarzanie wyników SQLAlchemy
To znaczy, że event loop poświęcał znaczną część czasu nie na bazę i nie na sieć, tylko na budowanie i serializację odpowiedzi.
Problem nr 1: kosztowna serializacja przez Pydantic
Endpoint zwracał dość duży obiekt:
class OrderResponse(BaseModel):
id: int
items: list[Item]
customer: CustomerNiektóre zamówienia miały ponad 200 pozycji. W efekcie dla każdego requestu zachodził taki łańcuch:
To wygodne, bezpieczne i estetyczne. Ale kosztowne, szczególnie jeśli odpowiedź jest duża, requestów jest dużo, a serializacja odbywa się przy każdym z nich.
Problem nr 2: klasyczne N+1 w SQLAlchemy
Drugi problem okazał się jeszcze bardziej banalny.
order = await session.get(Order, order_id)
items = order.itemsRelacja items ładowała się leniwie. Jeśli zamówienie miało 200 pozycji, bardzo łatwo oznaczało to 200 dodatkowych zapytań SQL.
Przy pojedynczym requestcie takie zachowanie może być mało zauważalne. Ale pod obciążeniem matematyka bardzo szybko staje się nieprzyjemna.
Co działo się przy każdym zapytaniu
W praktyce serwis robił mniej więcej to:
- 1 zapytanie po Order
- do 200 zapytań po Items
- tworzenie setek obiektów Pydantic
- serializację odpowiedzi do JSON
Osobno każda z tych operacji wyglądała “niewinnie”. Razem zamieniały serwis w kolejkę, a latency uciekało w sekundy.
Co zrobiliśmy
1. Usunęliśmy N+1 przez eager loading
Przenieśliśmy ładowanie powiązanych encji na selectinload:
stmt = (
select(Order)
.options(selectinload(Order.items))
.where(Order.id == order_id)
)
result = await session.execute(stmt)
order = result.scalar_one()Po tej zmianie schemat wyglądał tak:
- 1 zapytanie po Order
- 1 zapytanie po Items
Już samo to mocno odciążyło serwis.
2. Zmniejszyliśmy narzut Pydantic tam, gdzie miało to sens
Było:
return OrderResponse.model_validate(order)Zmieniliśmy na:
return {
"id": order.id,
"items": [{"id": i.id, "price": i.price} for i in order.items],
}W naszym przypadku niemal dwukrotnie zmniejszyło to latency.
Ważne: nie zrezygnowaliśmy z Pydantic całkowicie. Zostawiliśmy go tam, gdzie naprawdę jest potrzebny, czyli na granicach systemu, do walidacji danych wejściowych i tam, gdzie istotny jest ścisły schemat. Ale przestaliśmy bez potrzeby przepuszczać przez niego w całości duże, zagnieżdżone obiekty.
3. Podłączyliśmy szybszy encoder JSON, czyli orjson
Dodaliśmy ORJSONResponse:
from fastapi.responses import ORJSONResponse
app = FastAPI(default_response_class=ORJSONResponse)Przy dużych odpowiedziach zysk był bardzo wyraźny: serializacja stała się około 3–5 razy szybsza. Konkretna liczba zależy od struktury danych, ale w naszym przypadku efekt był zdecydowanie odczuwalny.
4. Zrównolegliliśmy zewnętrzne zapytania
Wcześniej zewnętrzne zapytania HTTP były wykonywane sekwencyjnie:
data1 = await client.get(url1)
data2 = await client.get(url2)
data3 = await client.get(url3)Przerobiliśmy to na wykonanie równoległe:
data1, data2, data3 = await asyncio.gather(
client.get(url1),
client.get(url2),
client.get(url3),
)Jeśli requesty są od siebie niezależne, daje to bardzo wyraźny zysk w czasie odpowiedzi.
Efekt po poprawkach
Po optymalizacjach serwis zaczął wytrzymywać 3–4 razy większe obciążenie.
Wnioski
- Async nie znaczy “szybko”. Asynchroniczność pomaga przeczekać I/O, ale nie ratuje przed ciężką serializacją i dodatkową pracą na CPU.
- N+1 długo pozostaje niewidoczne. Przy małym obciążeniu taki kod może wyglądać całkiem poprawnie. Pod ruchem bardzo szybko zamienia się w poważne wąskie gardło.
- Duże odpowiedzi są kosztowne. Im większy obiekt odpowiedzi, tym wyższy koszt serializacji, walidacji i transformacji.
- Najpierw profilowanie, potem optymalizacja. Inaczej łatwo stracić czas na poprawianie nie tego fragmentu systemu, który naprawdę spowalnia całość.
Co sprawdzić, jeśli FastAPI nagle zwolniło
- czy nie ma blokującego kodu:
requests, synchronicznych klientów albo ciężkich operacji w Pythonie - czy nie ma N+1 w ORM
- ile czasu zajmuje serializacja w Pydantic
- jakiego JSON-encodera używasz
- czy workers, timeouty i limity serwera są dobrane sensownie
Podsumowanie
Czasem problem nie leży w bazie. Czasem nie leży w sieci. Czasem nie chodzi nawet o zewnętrzne serwisy.
Czasem wszystko sprowadza się do tego, jak dokładnie budujesz i serializujesz odpowiedź. I szczerze mówiąc, to jedno z częstszych i bardziej nieprzyjemnych produkcyjnych zaskoczeń w serwisach pisanych w Pythonie.