Jak zdekomponowaliśmy komponent Angulara liczący 2800 linii kodu i czego nas to nauczyło
We frontendzie prosty ekran może bardzo łatwo zamienić się w komponent, który rośnie szybciej, niż architektura wokół niego jest w stanie się dostosować. W pewnym momencie taki plik staje się trudny do czytania, ryzykowny w modyfikacji i niemal niemożliwy do rozwijania bez efektów ubocznych. Dokładnie z tym spotkaliśmy się w jednym z naszych projektów Angularowych.
Jak komponent wymknął się spod kontroli
Na początku ekran był dość prosty, więc trzymanie wszystkiego w jednym komponencie wydawało się rozsądnym wyborem. Przyspieszało to development i ułatwiało pierwsze iteracje.
Ale wymagania stale rosły. Dodaliśmy strefy drag-and-drop oparte na Angular CDK, karty z renderowaniem zależnym od kontekstu, animacje przejść i efekty wizualne powiązane ze stanem ekranu.
Po kilku sprintach komponent urósł do 1800 linii szablonu i 1000 linii logiki. Szablon stał się przeciążony warunkowym markupem: ten sam element UI był renderowany inaczej w zależności od statusu, typu danych i uprawnień użytkownika. Znalezienie właściwej sekcji zajmowało minuty, a zmiana jednego bloku mogła łatwo wpłynąć na inny.
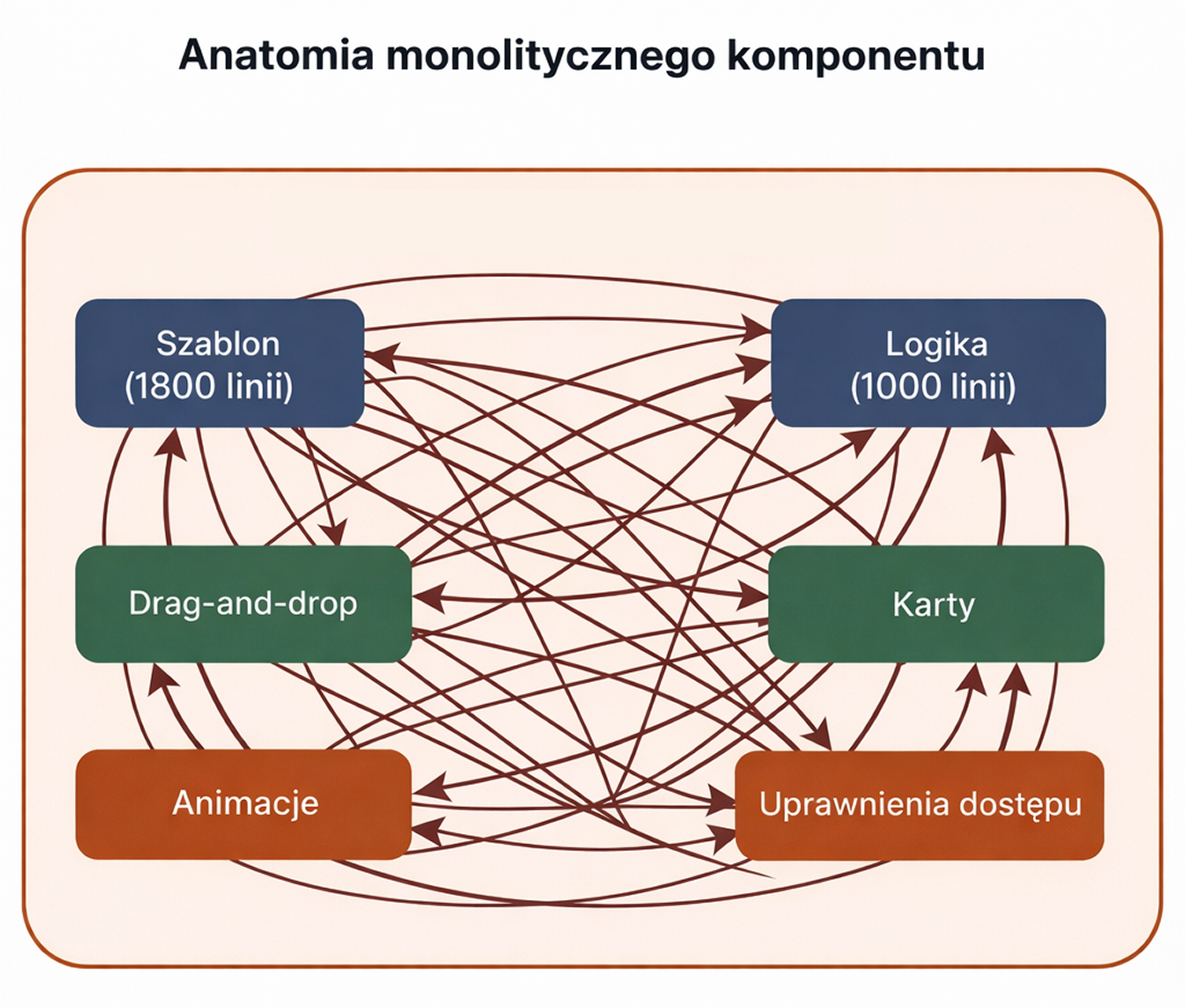
Schemat 1. Anatomia monolitycznego komponentu
Dlaczego nie mogliśmy po prostu tego „podzielić”
Problemem nie była tylko ilość kodu, ale też to, jak mocno powiązana była logika.
Drag-and-drop był rozrzucony po wielu częściach komponentu: przeniesienie karty wpływało jednocześnie na kilka obszarów interfejsu. Renderowanie zależało od stanu, typu danych i uprawnień użytkownika. Style, animacje i warunki renderowania również były ściśle powiązane ze stanem komponentu nadrzędnego.
Kolejnym wyzwaniem było to, że development się nie zatrzymał. Inni programiści nadal wprowadzali zmiany w tym samym pliku, więc refaktoryzację trzeba było przeprowadzać stopniowo, bez długiej izolacji w osobnym branchu.
Największą trudnością nie był sam rozmiar pliku, ale to, że szablon, logika, stan i interaktywność były już zbyt mocno ze sobą splecione.
Jak podeszliśmy do refaktoryzacji
Zaczęliśmy od podzielenia ekranu na sensowne bloki i zdefiniowania dla każdego z nich trzech rzeczy:
- jakie dane otrzymuje;
- jakie zdarzenia emituje;
- od której części stanu komponentu nadrzędnego zależy jego zachowanie.
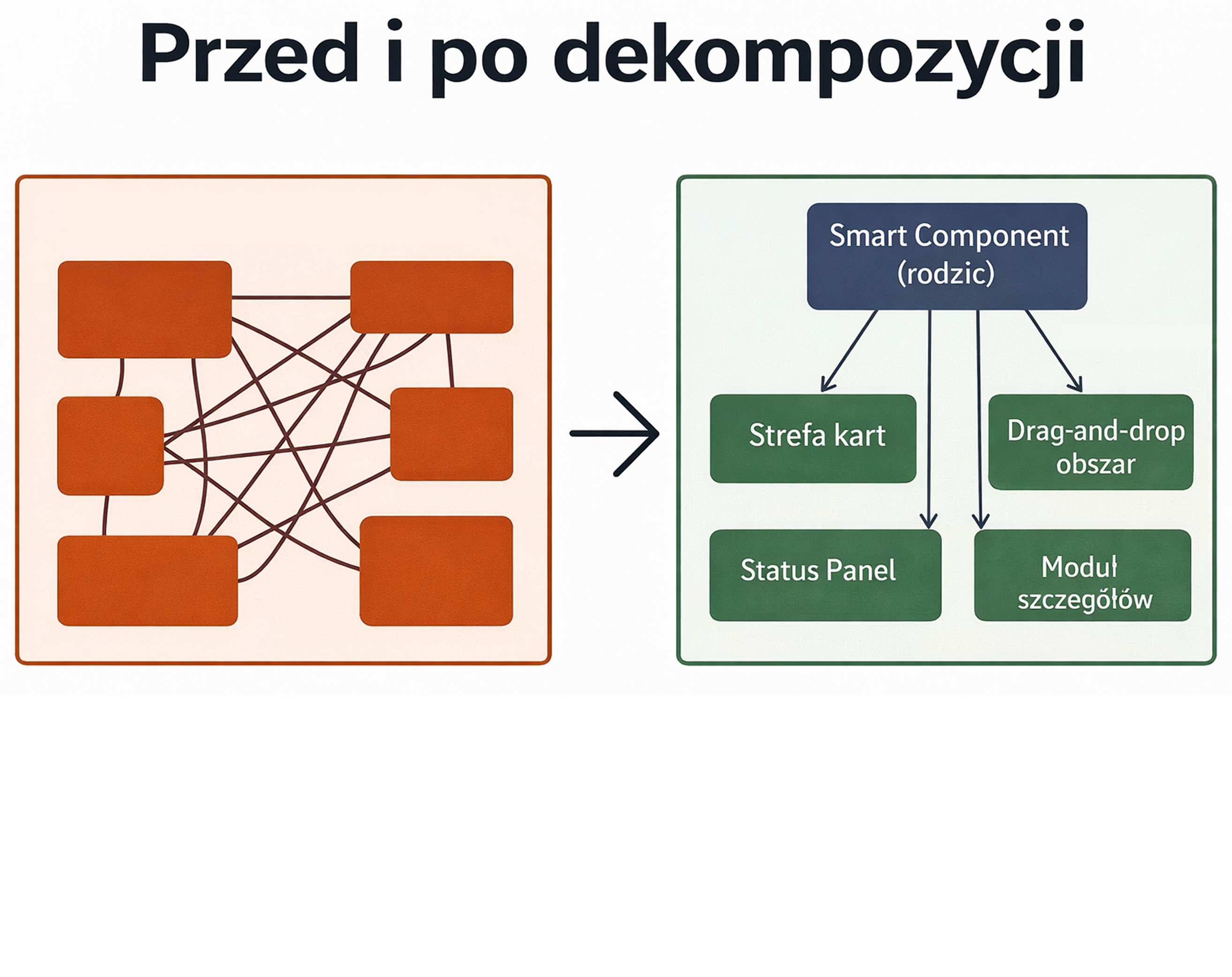
Schemat 2. Przed i po: dekompozycja Smart/Dumb
Jako bazowe podejście wybraliśmy wzorzec Smart/Dumb components. Komponent nadrzędny pozostał „smart”: zachował dane, koordynację stanu i współdzieloną logikę ekranu. Komponenty podrzędne przejęły renderowanie, lokalne interakcje oraz komunikację przez czytelne API oparte na @Input() i @Output().
Refaktoryzacja zajęła od trzech do czterech dni skupionej pracy. Przenosiliśmy bloki stopniowo, weryfikowaliśmy zachowanie wizualne i dopiero wtedy przechodziliśmy do kolejnej części. Aby nie zakłócać równoległego developmentu, synchronizowaliśmy się z zespołem kilka razy dziennie i regularnie mergowaliśmy zmiany do głównego brancha.
Co okazało się najtrudniejsze
Najtrudniejszą częścią było rozdzielenie drag-and-drop.
W oryginalnej implementacji logika przemieszczania była ściśle powiązana z reprezentacją wizualną i stanem różnych stref. Musieliśmy zachować aktualne zachowanie bez regresji, a jednocześnie nie przenieść starego sprzężenia do nowych komponentów.
Ostatecznie zorganizowaliśmy interakcję tak, aby komponenty podrzędne odpowiadały wyłącznie za lokalne renderowanie i zdarzenia, podczas gdy komponent nadrzędny wiedział tylko o samym przemieszczeniu i po swojej stronie aktualizował ogólny stan ekranu.

Schemat 3. Jak rozdzieliliśmy drag-and-drop między komponentami
Efekt końcowy
Technicznie zadanie zostało wykonane na czas. Monolit zamienił się w zestaw czytelnych, wielokrotnego użytku komponentów z jasno określonymi kontraktami.
Niedługo później klient zmienił jednak koncepcję ekranu. Układ stref się zmienił, część scenariuszy kart została połączona, a drag-and-drop otrzymał inny model interakcji.
Niektóre elementy nowej architektury dałoby się wykorzystać ponownie, ale utrzymywanie dwóch równoległych wariantów bardziej komplikowało kod, niż uzasadniały to korzyści. Ostatecznie branch z refaktoryzacją został zarchiwizowany.
Ten case okazał się przydatny nie tylko jako ćwiczenie z refaktoryzacji, ale także jako przypomnienie, jak silnie decyzje architektoniczne zależą od kontekstu produktu.
Nawet technicznie poprawne rozwiązanie może stracić sens, jeśli zmienia się sam ekran i jego przepływy użytkownika.
Co wynieśliśmy z tego case’u
1. Nawet planowana refaktoryzacja musi być zgodna z roadmapą
Nawet jeśli potrzeba techniczna jest oczywista, ważne jest, by zrozumieć, czy nadchodzące zmiany nie wpłyną na samą strukturę ekranu.
2. Dekompozycję najlepiej zrobić, zanim komponent stanie się krytycznie złożony
Jeśli jeden plik zaczyna zawierać dane, renderowanie, warunkową logikę wyświetlania i koordynację złożonych interakcji, to wyraźny sygnał, że komponent należy podzielić.
3. Nawet jeśli konkretna implementacja nigdy nie trafia na production, wysiłek inżynierski nie idzie na marne
Podejścia do rozdzielania odpowiedzialności, projektowania API komponentów i enkapsulacji złożonych zachowań UI można później wykorzystać w innych projektach i dzięki nim zespoły szybciej podejmują lepsze decyzje.
Ten case przypomniał nam, że refaktoryzacja nie dotyczy wyłącznie jakości kodu, ale także kontekstu produktu. To właśnie połączenie dyscypliny inżynierskiej i świadomości zmian biznesowych sprawia, że development staje się naprawdę dojrzały.