
Użytkownik wysyła żądanie płatności i czeka na wynik.
Jedna transakcja może zakończyć się sukcesem. Druga, z zewnątrz prawie taka sama, może natrafić na błąd na jednym z etapów przetwarzania.
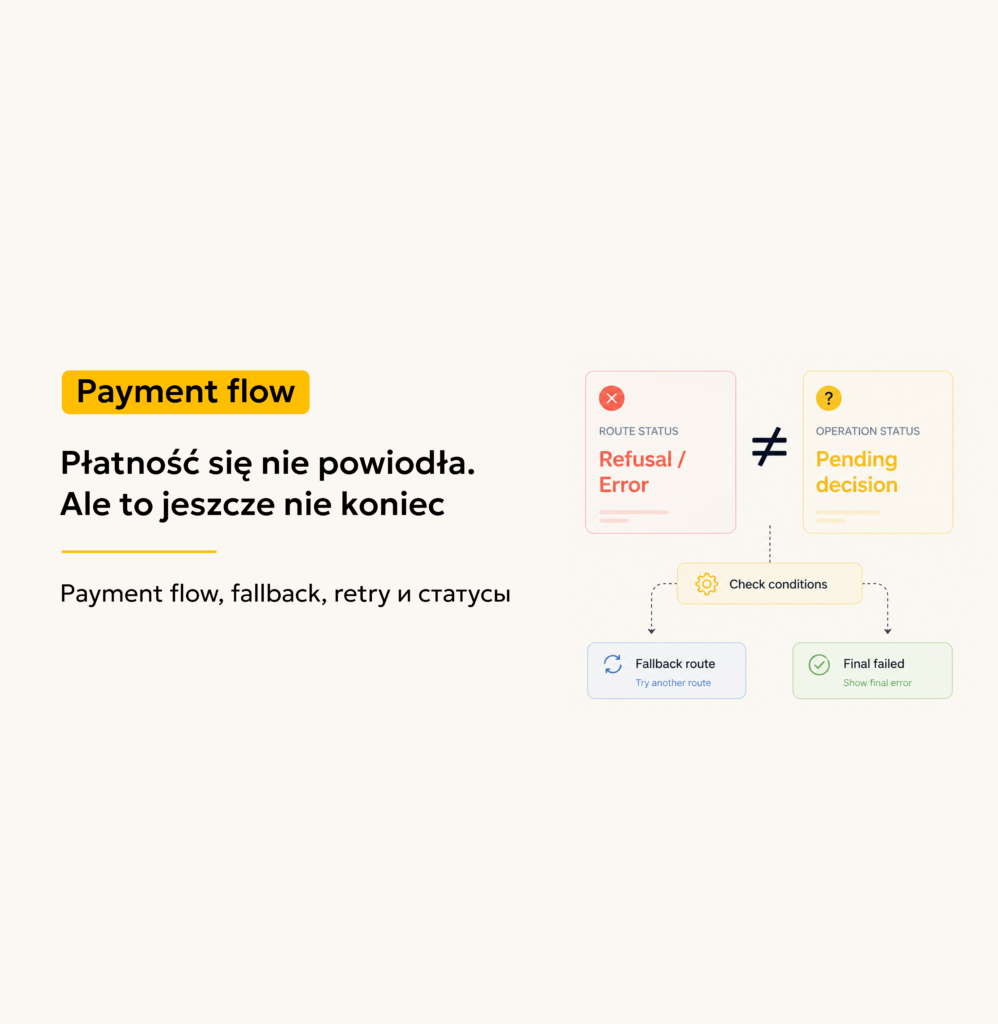
Dla użytkownika wynik wygląda prosto: płatność się nie powiodła.
Ale dla payment flow nie zawsze jest to ta sama sytuacja.
Czasem operację naprawdę trzeba zatrzymać. Na przykład wtedy, gdy odmowa wynika z danych, warunków operacji albo finalnej odpowiedzi, po której ponowne przetwarzanie nie jest dozwolone.
A czasem zawiodła tylko wybrana ścieżka przetwarzania. Nie mogła przyjąć albo obsłużyć żądania, choć sama operacja nadal może zostać przeprowadzona inną dopuszczalną drogą.
Jeśli system nie rozróżnia tych przypadków, może zbyt wcześnie zwrócić failed payment. Nie dlatego, że operacji nie da się przeprowadzić, ale dlatego, że wybrana ścieżka przetwarzania nie zadziałała.
W artykule omawiamy
Jeden błąd na ekranie, różne przyczyny wewnątrz flow
Na ekranie wszystko wygląda tak samo: płatność się nie powiodła.
Wewnątrz systemu mogą jednak stać za tym różne przyczyny.
Dane albo warunki operacji
Jeśli problem dotyczy danych albo warunków operacji, proces trzeba zatrzymać.
Odpowiedź bez ponownego przetwarzania
Infrastruktura płatnicza może zwrócić odpowiedź, po której ponowne przetwarzanie nie powinno być uruchamiane.
Błąd ścieżki przetwarzania
Ścieżka może zwrócić odmowę albo błąd, po których system może sprawdzić alternatywny scenariusz.
Jeśli te sytuacje zostaną pomieszane, flow działa zbyt topornie: otrzymał odmowę, pokazał błąd, zakończył proces.
Błąd ścieżki nie zawsze oznacza, że cała operacja powinna zakończyć się jako failed payment.
Gdzie psuje się liniowy payment flow
Prosty scenariusz wygląda tak:
Liniowa logika kończy proces zbyt wcześnie
Dopóki płatności przechodzą pomyślnie, problem jest prawie niewidoczny. Żądanie zostało wysłane, system otrzymał pozytywną odpowiedź, a użytkownik zobaczył końcowy status.
Słaby punkt pojawia się po odmowie albo błędzie na ścieżce przetwarzania.
W tym momencie system musi zrozumieć, jaka odpowiedź przyszła z banku, providera albo wewnętrznego procesora i co można zrobić dalej.
Zwykle trzeba rozróżnić:
Jeśli fallback jest dopuszczalny, system może sprawdzić inną ścieżkę przetwarzania. Jeśli nie, flow powinien się zakończyć i zwrócić użytkownikowi końcowy status.
Bez tego rozróżnienia użytkownik może otrzymać błąd nie dlatego, że płatność jest niemożliwa, ale dlatego, że wybrana ścieżka przetwarzania nie zadziałała.
Co flow powinien zrobić po błędzie ścieżki
Po błędzie jednej ze ścieżek system nie powinien automatycznie reagować przez “pokaż błąd” albo “powtórz próbę”.
Najpierw trzeba określić, jaka odpowiedź przyszła i czy można kontynuować przetwarzanie.
Flow powinien sprawdzić
Przyczynę odmowy
Czy odmowa dotyczy danych albo warunków operacji.
Krok użytkownika
Czy użytkownik widział już krok potwierdzenia płatności.
Alternatywną ścieżkę
Która ścieżka jest dopuszczalna i nie pogorszy scenariusza dla użytkownika.
Końcową odpowiedź
Czy użytkownik powinien już zobaczyć błąd.
To ważne dla scenariusza użytkownika. Jeśli osoba przeszła już do potwierdzenia płatności, a po odmowie system pokaże jej kolejny podobny krok potwierdzenia przez inną ścieżkę, może to wyglądać podejrzanie i obniżyć zaufanie.
Dlatego fallback powinien uwzględniać nie tylko techniczną odpowiedź ścieżki, ale też to, co użytkownik już zobaczył.
Flow ze sprawdzeniem warunków
Dla użytkownika ścieżka nie powinna stać się dłuższa. Nie wybiera on trasy, nie wpisuje danych ponownie i nie uruchamia płatności jeszcze raz.
Dlaczego fallback nie powinien być sprowadzany do retry
W teorii fallback brzmi prosto: wybrana ścieżka nie zadziałała, więc próbujemy drugiej.
W płatnościach taka logika szybko tworzy ryzyka, jeśli nie zostanie ograniczona regułami.
Fallback nie powinien uruchamiać się przy każdym failed payment. Jeśli odmowa wynika z danych użytkownika, finalnej odpowiedzi infrastruktury płatniczej albo scenariusza, w którym ponowne przetwarzanie jest niedopuszczalne, flow powinien się zatrzymać.
Alternatywna ścieżka ma sens tam, gdzie odmowa dotyczy ścieżki przetwarzania albo awarii technicznej, a nie samej możliwości przeprowadzenia operacji.
Fallback nie powinien odpowiadać na pytanie “co zrobić po błędzie?”. Powinien odpowiadać na pytanie “jakie warunki sprawiają, że ponowne przetwarzanie jest dopuszczalne?”.
Dlatego fallback powinien opierać się na regułach. Nie “coś poszło nie tak, spróbujmy jeszcze raz”, ale “ten typ odpowiedzi dopuszcza kolejną ścieżkę”.
Ten sam status może wymagać różnych działań w zależności od reguł routingu i stanu operacji. W jednym przypadku proces trzeba zakończyć od razu. W innym można sprawdzić alternatywną ścieżkę. Bez takiej logiki fallback zamienia się w zestaw przypadkowych powtórnych prób, a zachowanie systemu staje się trudne do przewidzenia.
Osobno trzeba kontrolować każdą próbę przetwarzania i zapisywać historię przebiegu operacji. To pomaga zrozumieć, które kroki zostały już wykonane, jakie odpowiedzi otrzymał system i w którym momencie proces powinien się zakończyć.
Dzięki temu fallback nie zamienia się w chaotyczny retry. System wykonuje ograniczoną i kontrolowaną próbę kontynuowania procesu, zamiast bez końca przepuszczać tę samą operację przez różne ścieżki.
Dlaczego tego nie da się dodać jednym warunkiem w kodzie
Jeśli payment flow był pierwotnie liniowy, fallback rzadko da się dodać małą poprawką.
Zmienia się nie tylko miejsce, w którym system wybiera ścieżkę. Dotyczy to również odpowiedzi z infrastruktury płatniczej, statusów, reguł zatrzymania procesu, powtórnych prób, końcowej odpowiedzi dla użytkownika i zarządzanych reguł routingu.
Jednocześnie stare scenariusze powinny nadal działać: udane płatności nie powinny zmieniać zachowania, finalne odmowy nie powinny trafiać do fallback, a alternatywna ścieżka powinna uruchamiać się tylko tam, gdzie ponowne przetwarzanie jest dopuszczalne.
Trudność nie polega na tym, że istnieje druga ścieżka. Trudność polega na tym, żeby wbudować ją w istniejący flow i nie stracić kontroli nad stanem operacji.
Co sprawdzić przed uruchomieniem fallback
Fallback dodaje do payment flow nowe rozgałęzienia. Trzeba je testować osobno, inaczej system może stać się bardziej złożony, ale nie bardziej niezawodny.
Minimalny zestaw scenariuszy
Szczególną uwagę warto zwrócić na scenariusze, w których stary flow wcześniej kończył się od razu. To właśnie tam nowa logika zmienia zachowanie systemu.
Na przykład jeśli alternatywna ścieżka również zwraca odmowę, flow powinien poprawnie zakończyć proces i zwrócić użytkownikowi wynik powiązany z przyczyną ostatniej odmowy. W przeciwnym razie zespół otrzyma operację o niejasnym stanie, a użytkownik niezrozumiały wynik.
Po co są zarządzane reguły routingu
Jeśli reguły fallback są twardo zapisane w kodzie, zespół płatniczy zależy od developmentu nawet przy zmianach operacyjnych.
Warunki przetwarzania mogą się zmieniać. Jedna ścieżka pasuje do jednych scenariuszy, a do innych już nie. Niektóre odmowy trzeba od razu traktować jako finalne. Inne można skierować do alternatywnego przetwarzania.
Dlatego w złożonych payment flow warto przewidzieć zarządzane reguły routingu.
Pomagają one określić, które scenariusze idą do fallback, które zatrzymują się od razu, jakie ścieżki są dostępne przy różnych warunkach i kiedy system powinien zwrócić finalną odmowę.
Takie reguły mogą zależeć od typu operacji, statusu odpowiedzi, dostępnych ścieżek i ogólnych warunków przetwarzania.
Reguła nie powinna odpowiadać na pytanie “co zrobić po błędzie?”, tylko na pytanie “jakie warunki sprawiają, że ponowne przetwarzanie jest dopuszczalne?”.
Co to daje produktowi
Główna wartość takiego flow polega na tym, że system przestaje mylić błąd ścieżki z błędem całej operacji.
Jeśli operacji naprawdę nie da się przeprowadzić, użytkownik otrzymuje finalną odmowę.
Jeśli wybrana ścieżka nie mogła obsłużyć żądania, ale istnieje dopuszczalny alternatywny scenariusz, system może sprawdzić inną drogę bez przerzucania ponownej próby na użytkownika.
To pomaga nie kończyć procesu zbyt wcześnie: użytkownik nie dostaje błędu tylko dlatego, że wybrana ścieżka nie mogła obsłużyć żądania.
Kiedy flow rozdziela finalne odmowy, statusy pośrednie i scenariusze fallback, zespołowi łatwiej zrozumieć, gdzie zatrzymała się operacja i dlaczego podjęto taką decyzję.
W podobnych systemach nie musi to całkowicie usuwać ręcznej analizy. Ale pomaga uczynić ją bardziej konkretną: zespół widzi nie tylko failed payment, ale cały łańcuch prób, odpowiedzi i warunków, które doprowadziły do końcowego statusu.
Co sprawdzić w swoim systemie
Jeśli w produkcie są płatności, routing żądań albo operacje ze statusami, zacznij od jednego pytania:
Co dokładnie wydarzyło się na ścieżce przetwarzania?
Pięć rzeczy, które warto sprawdzić
Jeśli system nie rozróżnia tych przypadków, może kończyć proces zbyt wcześnie. Użytkownik zobaczy błąd, a zespół będzie analizować operacje, które mogły przejść według innej dopuszczalnej logiki.
Słaby payment flow widzi odmowę i kończy proces.
Dobry flow najpierw rozumie, co dokładnie zawiodło. Dopiero potem decyduje, czy zatrzymać operację, czy kontynuować przetwarzanie.
Chcesz sprawdzić swój payment flow?
Jeśli w twoim systemie są płatności, statusy, routing albo powtórne próby, warto zobaczyć, gdzie flow może kończyć proces zbyt wcześnie.
El Pixel pomaga analizować takie scenariusze: od scenariusza płatności po logikę statusów, błędów, fallback i reguł przetwarzania.
Możemy przejrzeć twój flow i pokazać, gdzie system zwraca błąd zbyt wcześnie, gdzie fallback może być ograniczony regułami i gdzie sporne sytuacje wymagają ręcznej analizy.


